Полное руководство по настройки очередей задач на Flask через Celery и RabbitMQ.
В Интернете сложно найти полноценное описание настройки Celery через RabbitMQ и Flask. В основном попадаются примеры на Redis и Django. В этой статье попробую это исправить и расскажу о полной настройке и запуске Celery на Flask.
Что такое очереди задач?
Это что-то вроде cron-задач, только более продвинутое использование. Celery позволяет запускать задачи не перегружая процессор (умеет распределять нагрузку). В отличии от cron задач celery может запускать задачи параллельно. Также имеется обработчики ошибок и легко следить за результатом.
В Celery встроен свой cron-обработчик. С этим мы получаем все преимущества celery и одновременно можем запланировать события по типу cron.
Зачем нужен RabbitMQ?
Из-за объема информацию RabbitMQ вынесен в отдельную статью.
А нужны ли вам очереди задач?
Очереди задач довольно замороченная штука. Вы можете увидеть это посмотрев на объем текущей статьи. Я постарался учесть большую часть для того, чтобы все настроить, но описано тут далеко не все.
А что делает в конечном счете celery? Если отбросить нюансы, он делает то же самое что и cron, но требует гораздо больше дополнительных сущностей, зависимостей и настроек.
Конечно с этой статьей учиться будет быстрее, но никто не гарантирует что вы не столкнетесь с другими проблемами или задачами не описанными здесь. Или допустим у вас будет не RabbitMQ, а Redis или не Flask, а Django. Тогда придется разбираться во многих других нюансах самостоятельно.
Возможно вы сможете обойтись cron-ом на питоне.
Или может быть вам подойдет зацикливание таймером (timer)? Несмотря на простоту таймера есть в нём одно большое преимущество: функция не будет выполнена второй раз прежде чем она завершится. Однако это можно решить с помощью кэша, об этом будет в этой статье.
Установка Celery на Flask
Установка:
Настройка «очередей задач» будет на той же архитектуре, что рассказывается в цикле основных статей в архитектуре проекта на Flask.
Ниже приведены 2 конфигурации: та к которой я пришел и та которая описана в примерах на Flask.
Моя конфигурация
__init__.py
Это основной файл инициализации, который запускается вместе с запуском приложения на Flask. Смотрите структуру проекта на Flask. В этом же файле настраиваются конфигурационные файлы Flask.
Расположение файла
В функцию create_app (основная функция создания приложения на Flask) добавим новые конфигурационные файлы:
app = Flask(__name__)
app.config.from_pyfile('../configs/private/celery.py')
app.config.from_pyfile('../configs/beatschedule.py')
return app
app = create_app()
beatschedule.py
Расположение файла:
Это конфигурационный файл в котором будут планироваться задачи. Его содержимое:
task_default_queue = 'ploshadka_queue'
BEAT_SCHEDULE = {
'updates': {
'options': {'queue': 'ploshadka_queue'},
'task': 'task_update',
'schedule': 30.0,
},
}
celery.py
Расположение файла:
Это приватный файл для сельдерея. Локальный конфиг будет отличаться от конфига продакшена. Этот конфиг обязательно должен быть добавлен в исключении файла .gitignore.
Его содержимое для PostgreSQL для локальной среды:
broker_url = 'pyamqp://guest@localhost//'
result_backend = 'db+postgresql+psycopg2://localhost/ploshadka_db'
beat_schedule = BEAT_SCHEDULE
также будет работать:
Для прода в result_backend добавляем пользователя БД и пароль, остальное аналогично тому что выше:
broker_url = 'pyamqp://guest@localhost//'
result_backend = 'db+postgresql+psycopg2://<пользователь>:<пароль>@localhost/ploshadka_db'
beat_schedule = BEAT_SCHEDULE
В старых инструкциях вместо result_backend указана константа CELERY_RESULT_BACKEND, но сейчас она считается deprecated и будет в последствии удалена.
В результате этой настройки брокер сообщений создаст две таблицы в БД, в которых будет хранить свои данные:


Задачи
Расположение задач:
--__init__.py
--updates.py
Внутри файла updates.py:
celery = Celery('updates')
@celery.task(name='task_update')
def task_update():
return "task_update: success"
name=’task_update’ должно равняться имени ‘task’: ‘task_update’ в BEAT_SCHEDULE.
Запуск
Обязательно запускать с опцией конфига. Обо всех этих и других командах (и опциях для них) будет описано подробнее ниже в текущей статье.
celery -A tasks.updates.celery --config=configs.private.celery worker -D --logfile=logs/celery.log -l INFO --purge
Классическая конфигурация Flask
Ближе к официальной доке для Flask, но использую то что выше, а это сохранил на память.
__init__.py
def make_celery(app):
celery = Celery(
app.import_name,
broker=app.config['CELERY_BROKER_URL'],
backend=app.config['RESULT_BACKEND'],
)
celery.conf.update(app.config)
# Настройки для cron
celery.conf.beat_schedule = app.config['BEAT_SCHEDULE']
return celery
config.py
Доступы к серверу сообщений RabbitMQ пропишем внутри файла config.py
Для локалки подключение к PostgreSQL:
CELERY_BROKER_URL='pyamqp://guest@localhost//'
RESULT_BACKEND='db+postgresql+psycopg2://localhost/bd_name'
На удаленном сервере:
CELERY_BROKER_URL = 'pyamqp://localhost'
RESULT_BACKEND = 'db+postgresql+psycopg2://user_name:password@localhost/bd_name'
Cron настройки
Если мы хотим запускать наши задачи через cron celery, то здесь же укажем настройки:
task_default_queue = 'ploshadka_queue'
BEAT_SCHEDULE = {
'updates': {
'options': {'queue': 'ploshadka_queue'},
'task': 'task_update',
'schedule': 30.0,
},
}
Вместо BEAT_SCHEDULE раньше было CELERYBEAT_SCHEDULE, но сейчас является устаревшей.
Создаём задачи
Под задачи отведем отдельную директорию, назовем её tasks. В ней создадим файл updates.py.
Внутри файла. Функция с аргументами:
celery = make_celery(app)
@celery.task()
def add(a, b):
return a + b
add.delay(1, 5)
Метод delay() отвечает за запуск нашей задачи (функции add).
Функция с именем:
def celery_update_balance():
update_deposit()
return {'status': 'Задача завершена!', 'result': 100}
celery_update_balance.delay()
Функция для запуска по крону:
def update_balance():
update()
return {'status': 'Задача завершена!', 'result': 100}
Варианты конфига cron
BEAT_SCHEDULE = {
'updates': {
'options': {'queue': 'ploshadka_queue'},
'task': 'task_update',
'schedule': 30.0, # Раз в 30 секунд
# Другие варианты:
# 'schedule': crontab(hour=5, minute=20, day_of_week=1),
# 'schedule': crontab(*), # Раз в минуту
# 'args': (16, 16) # Аргументы у функции
},
}
Запуск задач вне крона (worker)
а) Мы запустили наше приложении.
б) Находимся внутри виртуального окружения python.
После этого запускаем:
где:
tasks — директория
updates — файл (модуль)
-l info — вывести мониторинг в консоли
Эта команда запустит worker и выполнит функцию с delay. Если все настроено было верно в базе данных появится новая запись, а в консоли отобразится информация о ходе работ:
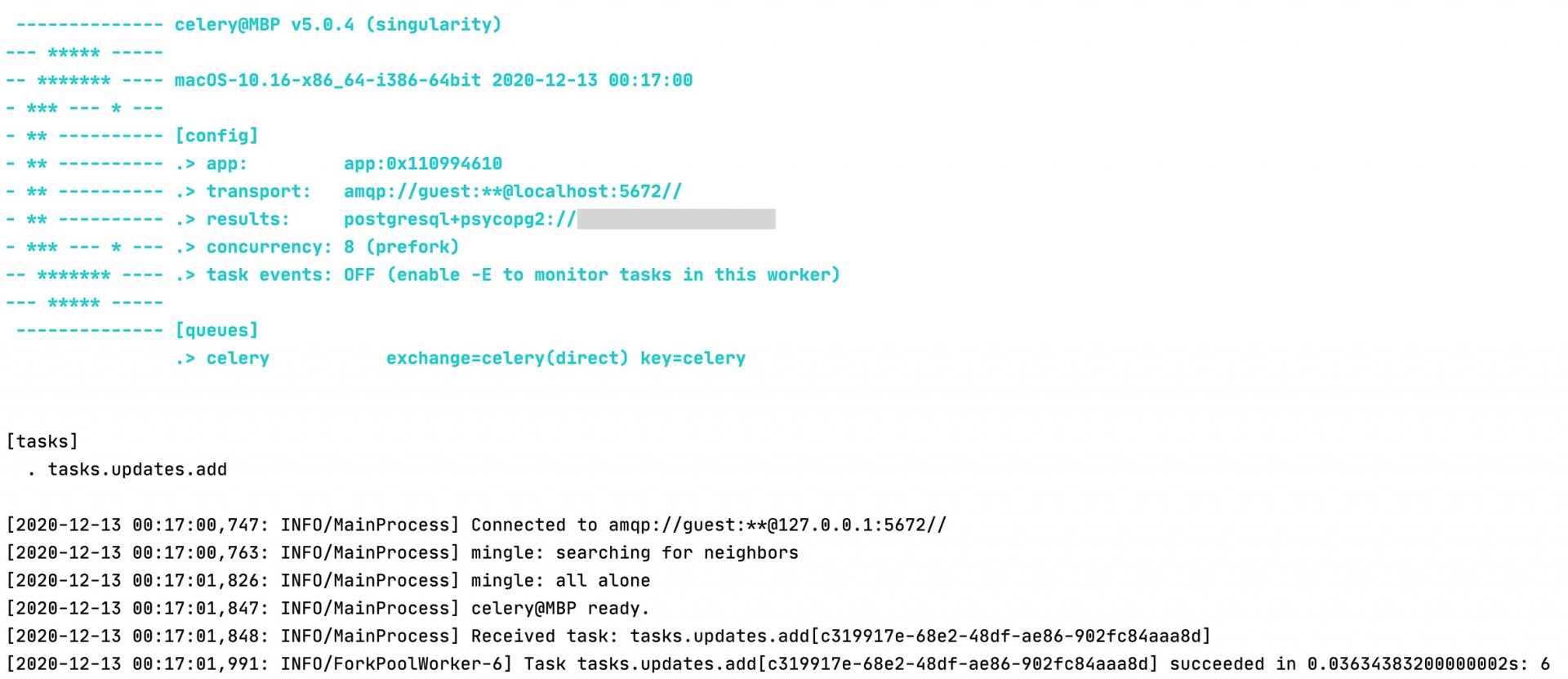
Если в команду выше докинуть атрибут -B, то в этом файле одновременно будут запущены все задачи, как с кроном, так и без него.
Предварительно надо запустить beat (об этом будет ниже).
Запуск воркера с -B использовать только для отладки, в противном случае задача может запускаться более одного раза. На боевом сервере команды запуска обычных задач и запланированных надо осуществлять отдельными командами.
Запуск задач по крону (beat)
Для запуска планировщика нужны две команды worker и beat. Важно запускать сначала worker, а потом beat. Иначе задача будет сделана 2 раза.
Задвоение задач можно избежать также, если запускать команды с очисткой очередей —purge.
Запускаем воркер:
В другой вкладке:
где:
detach — запуск в «тихом» (демон) режиме (без блокировки консоли). Для worker можно использовать вместо detach опцию -D.
worker тоже можно запускать с detach:
celery -A tasks.updates.celery beat --detach
Сначала запускается worker и он начинает мониторинг и обработку очередей задач. Затем туда с помощью beat добавляются задачи, которые подхватываются и выполняются worker-ом.
Запуск на сервере
На сервере запуск можно сделать через демонов. Но мне нравится запускать через detach. Так больше контроля в одном месте.
Если используется «моя конфигурация», то запуск осуществляется:
celery -A tasks.updates.celery --config=configs.private.celery worker --purge -l INFO --logfile=logs/celery.log -D
Если используется «классическая конфигурация Flask», то для beat:
А вот команда worker может не видеть всего что указано в make_celery и для этого надо прописать в ней все опции. При этом т.к. мы не создавали конфиг отдельный, то конфиг тоже указываем, но ссылаемся на модуль с задачей. Не знаю почему такие костыли, но только так оно работает в этом случае:
Работа с очередями
Очереди нужны, чтобы не запутаться внутри кролика, если сайтов на сервере несколько или задач очень много, то их лучше поделить на категории.
По умолчанию используется очередь с названием celery.
Для того чтобы добавить очередь к задачи надо добавить в конфиг следующее:
'updates': {
'options': {'queue': 'ploshadka.net'},
},
}
В случае запуска worker с определенной очередью:
Можно избежать запуск с указанием очереди прописав в файле __init__.py (там где мы инициализируем функцию celery):
Или указать в конфигурационном файле:
Проверка очередей
Предварительно должен быть запущен worker.
Показать какие задачи сейчас в работе:
Для проверки есть ещё такие команды, но они не покажут название текущей рабочей задачи как это сделает команда выше:
celery inspect active
celery inspect scheduled
Логирование в Celery
Celery перехватывает логирование тех задач, которые она выполняет. Даже если для тех задач настроено логирование, оно будет записываться в лог celery, а не в тот который был ранее указан в логировании.
Это можно переопределить добавив в конфигурацию создания make_celery такую директиву:
Для того чтобы логи записывались мы можем указать их в консольной команде:
Стоит обратить внимание, что одновременно с указанием файла —logfile=logs/celery.log надо указать, что именно будет записываться -l INFO.
Вместо info можно записывать дебаг: -l DEBUG. Использовать на случай отладки, иначе слишком много дополнительной информации будет записано.
Для beat точно такая же система.
Задвоения и дубликаты задач
Как было сказано выше дубли задач celery будут, если сначала добавляются beat, а потом запускать worker или если перед запуском воркера не очищать задачи.
Удалить повторы задач можно командами ниже. Иногда не сразу происходит удаление, нужно подождать около минуты.
Как удалить и очистить задачи ниже.
Как удалить задачи
Показать все планировщики celery:
Вывод:
501 83252 59866 0 11:52PM ttys001 0:00.00 grep celery
Завершить все задачи и планирощик:
Или эту (они должны были бы заменять друг друга, но на деле иногда одна из команд отказывается работать корректно):
После этой команды возникает надпись:
Можно не обращать внимание. Все воркеры и планировщики останавливаются. Это можно проверить командой выше (grep).
Как очистить или удалить очереди
Если запустить планировщик beat без worker, он все равно начнет работать. Это значит, что в нужное время будет добавлена задача в очередь. Иными словами, если была запланирована задача, которая каждую минуту что-то делает, то каждую минуту будет добавлена выполнение этой задачи. Очередь задач можно увидеть в RebbitMQ:
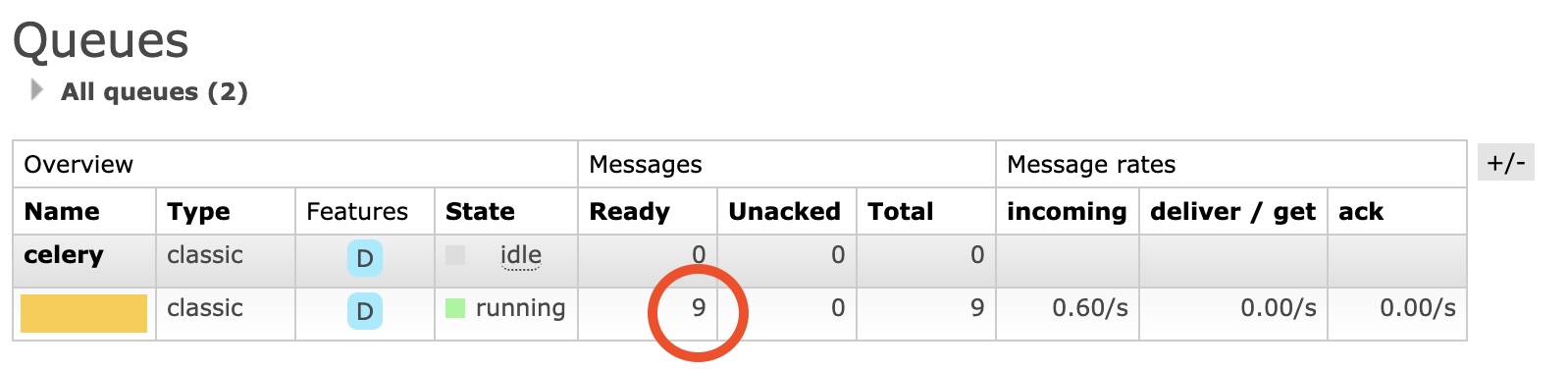
В тот момент когда будет запущен воркер, все накопленные задачи будут запущены друг за другом без того интервала, который раньше подразумевался (например, 1 минута). Это может привести к неприятным последствиям.
1
Удалить очереди конкретной задачи:
Должно показать что-то вроде:
2
Удалить очередь по её названию.
Теперь до запуска нового worker ничего накапливаться не будет, потому что мы вовсе удаляем очередь, а не просто очищаем ее.
3
Можно сразу запускать воркер с очищением очереди:
Как не повторять задачу пока она не завершится
Встроенных инструментов для этого не придумано. Надо самостоятельно делать блокировку внутри функции с помощью кэша. Можно сделать так:
is_running = cache.get("running")
# Если кэш есть, значит предыдущая функция не закончена, выйдем из функции
if is_running:
return
# Ставим кэш.
cache.set('running', '1')
# Удалим кэш в конце функции
cache.delete("running")
Дебаг
Если ничего не работает, попробовать найти ошибку через команды с дебагом.
Для worker в консоли или в режиме демона:
celery -A tasks.updates.celery worker --purge -l DEBUG --logfile=logs/celery.log -D
Для beat:
celery -A tasks.updates.celery beat -l DEBUG --logfile=logs/beat.log --detach
Celery Flower
Для просмотра задач воспользуетесь flower. Альтернативные варианты вывести на фронт данные из бд таблицы celery_taskmeta или просматривать данные там напрямую, например, через DataGrip.
Настройка конфигов
При запуске worker в режиме detach может возникнуть такая ошибка:
[2020-12-31 11:11:35,802: ERROR/MainProcess] Received unregistered task of type ‘task_update’.
The message has been ignored and discarded.Did you remember to import the module containing this task?
Or maybe you’re using relative imports?Please see
http://docs.celeryq.org/en/latest/internals/protocol.html
for more information.The full contents of the message body was:
‘[[], {}, {«callbacks»: null, «errbacks»: null, «chain»: null, «chord»: null}]’ (77b)
Traceback (most recent call last):
File «venv/lib/python3.9/site-packages/celery/worker/consumer/consumer.py», line 562, in on_task_received
strategy = strategies[type_]
KeyError: ‘task_update’
Дело в том, что worker не видит путь к задачам. Исправить можно двумя вариантами.
Вариант 1
Использовать в командной строке указатель на файл конфигурации, в котором описать настройки. Для этого в консольной команде надо указать:
где configs это директория в которой находится файл конфигурации celery-config.py.
Содержимое этого файла:
imports = ('tasks.updates',)
В импорте указываем путь до файла с задачами.
Вариант 2
Во втором варианте больше писанины, но так тоже будет работать: можно без указания дополнительных настроек в файле.
В самом BEAT_SCHEDULE указать полный путь до задачи:
'every_minute': {
'options': {'queue': 'task'},
'task': 'tasks.updates.task_update',
'schedule': 59.0,
},
}
где tasks.updates это директория и файл:
--__init__.py
--updates.py
А task_update название функции в файле updates.py.
В этом случае в самой задаче тоже обязательно указать полный путь:
def task_update():
return "Все ок"
Также все равно придется добавлять в командную строку опцию, но указывать уже на сам модуль с задачей:
Несколько очередей для разных сайтов на одном сервере
Добавляем такой атрибут к команде по запуска worker:
где каждая цифра под отдельный сайт, т.е. для второго сайта будет 2
Ошибка когда не указан параметр:
celery@domain1 ready.warnings.warn(W_PIDBOX_IN_USE.format(node=self))you give each node a unique node name!Or if you meant to start multiple nodes on the same host please make sure
Maybe you forgot to shutdown the other node or did not do so properly?
2021-01-10 22:38:19,893: venv/lib/python3.8/site-packages/kombu/pidbox.py:72:
UserWarning:
A node named celery@domain1 is already using this process mailbox!
2021-01-10 22:38:19,875: mingle: all alone2021-01-10 22:38:18,816: mingle: searching for neighbors
2021-01-10 22:38:18,802: Connected to amqp://guest:**@127.0.0.1:5672//
Не работает сохранение в БД
Если через worker detach не работает сохранение в БД, то ошибка аналогично предыдущей. Мы или указываем в файле конфигурации такие настройки:
result_backend = 'db+postgresql+psycopg2://localhost/ploshadka_net_db'
Или к консольной команде worker добавляем наш бэкенд:
Не запускается очередь
Ровно такая же ситуация с очередями. Можно указывать в консольной команде:
Или занести в файл конфигурации:
task_default_queue = 'ploshadka_queue'
Если не указывать очередь по умолчанию в конфигурации и не указывать ее в консольной команде, то в логах можно наблюдать такие надписи:
DEBUG/MainProcess] heartbeat_tick : for connection
Другие ошибки в процессе настройки
Scheduler: Sending due task every_minute
Ошибка:
LocalTime -> 2020-12-16 10:12:49
Configuration ->
. broker -> amqp://guest:**@localhost:5672//
. loader -> celery.loaders.app.AppLoader
. scheduler -> celery.beat.PersistentScheduler
. db -> celerybeat-schedule
. logfile -> [stderr]@%INFO
. maxinterval -> 5.00 minutes (300s)
[2020-12-16 10:12:49,940: INFO/MainProcess] beat: Starting…
[2020-12-16 10:13:00,017: INFO/MainProcess] Scheduler: Sending due task every_minute (tasks.update_balance)
Запущен beat, но не запущен worker.
Ошибка:
Error: no such option: —config
В новой версии celery изменилось расположение конфигов. Надо поставить опцию с конфигом перед beat или worker.
Также могут быть такие ошибки:
- Warning: Bottle installation failed: building from source
- AttributeError: ‘Flask’ object has no attribute ‘user_options’
- consumer: Cannot connect to amqp://guest:**@127.0.0.1:5672//
- Error: homebrew-core is a shallow clone
- The ‘CELERY_RESULT_BACKEND’ setting is deprecated and scheduled for removal in
- https://ploshadka.net/valueerror-invalid-width-2-must-be-0/
Сравнение версий Celery 4 и Celery 5
В четвертой версии Celery при запуске создавал pid файл с номером процесса внутри. Это было и плюсом и минусом. Плюс в том, что нельзя было запустить команду beat или worker дважды, показывало ошибку:
Seems we're already running? (pid: 34944)
А минус, чтобы убить процесс надо было использовать команду:
А она убивала не только процессы одного сайта, но и процессы celery для всех других сайтов. Начиная с версии 5, можно использовать команду:
Еще одно изменение в порядке опций в команде:
Теперь config и некоторые другие опции надо ставить перед worker, как показано выше.
Еще изменились константы. Вместо них сейчас переменные с другим наименованием.
Конечно это не все изменения, остальные можно узнать в официальных источниках.
Окончательный вариант запуска на сервере
Запускаем несколько worker:
celery --config=configs.private.celery worker -Q analyse -D --purge -l INFO --logfile=logs/celery.log
И запускаем только один beat:
Импорты указаны в файле beatschedule и в команде их дублировать не нужно:
Для перезапуска используем (осторожно, убивает все воркеры и биты):
и повторяем запуск снова.
