Немного более подробно о кодировках в реляционной базе данных PostgreSQL.
Базы данных по умолчанию
Введем команду:
Если мы только установили PostgreSQL, то там увидим такой список баз данных (List of databases):
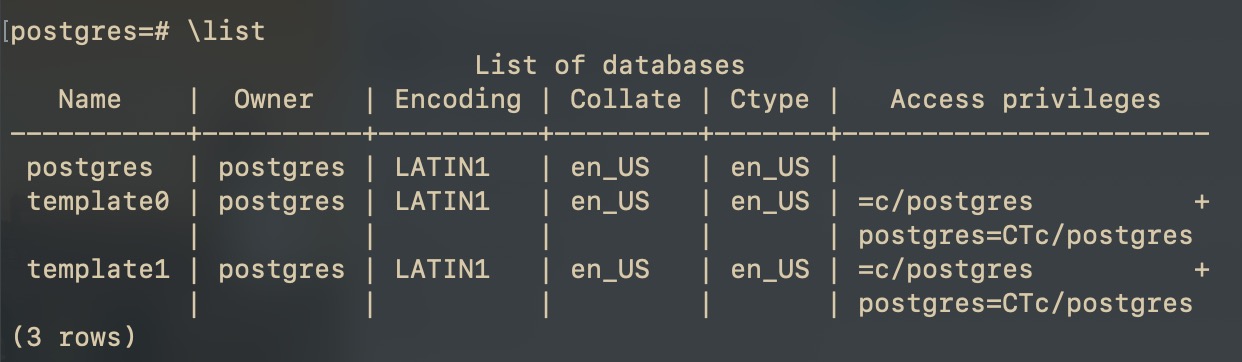
В зависимости от установленной операционной системы в колонках encoding, collate и ctype можно увидеть разные кодировки.
Пока нас интересуют названия баз данных: template1 и template0.
Эти базы данных являются шаблонами для создания новых баз данных. Другими словами: по образу и подобию их будут созданы позже другие базы данных.
template0 — это шаблон базы данных с первоначальными настройками. Эту БД стоит оставить такой какая она есть.
template1 — этот шаблон используется по умолчанию при создании новых баз данных. Здесь мы можем менять атрибуты, которые потом будут заимствованы для новых баз данных созданных по этому шаблону.
Проблема кодировок
Различия в кодировках
Для того чтобы мигрировать данные с локальной базы данных на базу данных на сервере или наоборот кодировки должны быть одинаковыми. В противном случае ошибка будет примерно такого плана:
Command was: INSERT INTO public.operations (id, user_id) VALUES (333, 1);
pg_restore: error: could not execute query: ERROR: character with byte sequence 0xd0 0x94 in encoding «UTF8» has no equivalent in encoding «LATIN1»
Разная сортировка в одинаковых кодировках
Даже если кодировки одинаковые, это всё равно может приводить к отличным результатам при сортировке. Автор по ссылке выше утверждает, что кодировка lc_collate = C решает эти проблемы.
Меняем кодировки LATIN1 на UTF8
Сначала разберем пару ошибок, которые могут возникать в процессе.
Эта ошибка возникнет, если пропустить первую команду и сразу попробовать переключиться на базу данных template0:
postgres-# \c template0
FATAL: database «template0» is not currently accepting connections
Previous connection kept
У следующей ошибки сложная история, но её избежим, когда принудительно укажем значения в LC_CTYPE и LC_COLLATE.
ERROR: encoding «UTF8» does not match locale «en_US»
DETAIL: The chosen LC_CTYPE setting requires encoding «LATIN1».
Теперь определим несколько базовых понятий.
LC_COLLATE — порядок сортировки строк
LC_CTYPE — классификация символов
Ниже команды смены локали для базы данных template1. Вместо ‘C’ можно использовать и другие значения, например: «en_US.UTF-8».
Сначала идет команда, если её выполнение будет успешным, то будет выведено значение такое же как указано здесь следом. Если ничего не выводится или выводятся другие сообщения, значит команды введены неправильно или с ошибками.
UPDATE 1
\c template0
You are now connected to database "template0".
update pg_database set datistemplate = FALSE where datname = 'template1';
UPDATE 1
drop database template1;
DROP DATABASE
При создании таблицы делаем её с кодировкой UTF8 и сортировкой C.
Важно для русской кириллицы, чтобы корректно работал поиск по базе данных, создавать такую:
Вариант без указания языка:
Или с en_US.UTF-8:
Продолжаем выполнять команды:
UPDATE 1
\c template1
You are now connected to database "template1".
update pg_database set datallowconn = FALSE where datname = 'template0';
UPDATE 1
Проверим результат:
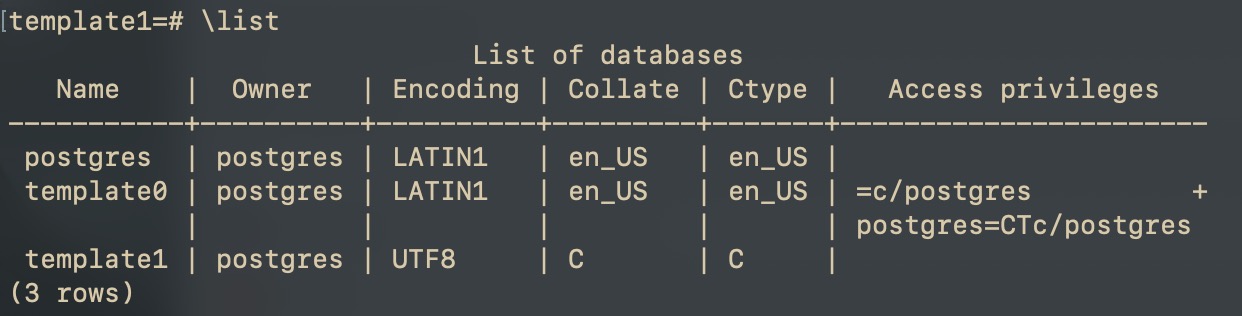
Теперь когда мы будем создавать таблицы они сразу будут у нас в нужной кодировке.
Альтернативный вариант
Этот вариант хоть и проще, но технически-правильно править эталонную таблицу, а на основании её уже создавать следующие таблицы. Однако можно обойтись и без этого и принудительно каждый раз создавать БД с нужными кодировками:
Результат будет таким же, как и в случае, если мы поменяли локаль у таблицы template1 и далее вне сеанса psql ввели команду:
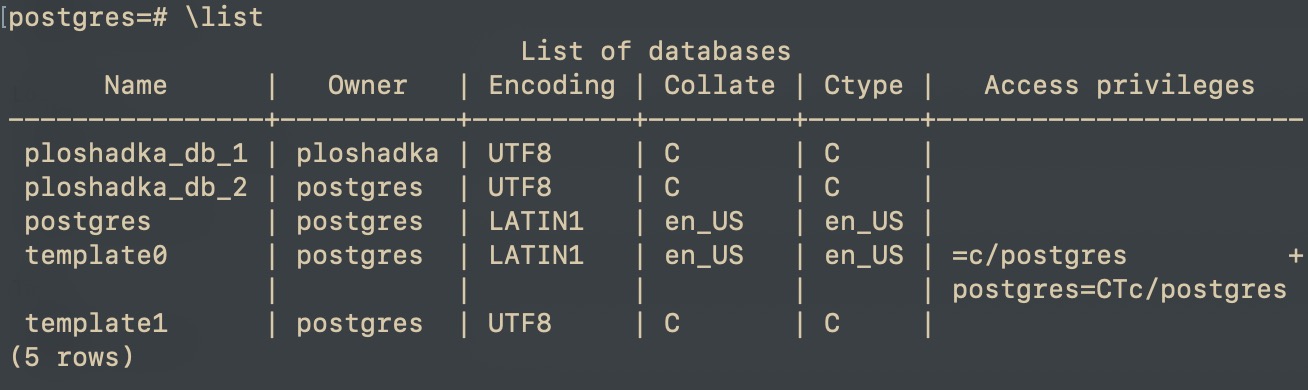
Тут можно заметить что пользователь postgres, а не ploshadka, но это легко поправимо, если создавать с указанием пользователя:
Альтернативный вариант всем вариантам
Проблема с кодировками могла и не возникать, если до установки PostgreSQL в самой системе заранее указать нужную кодировку — изменение локали на сервере.
